
Junior Alves
Senior Developer
Foto: Unsplash
Atualizado: 26 de novembro de 2025 às 08:25
Leitura: 8 minutos de leitura
Criado: 14 de setembro de 2025
Cache - O Guia Completo
Quando você NÃO deveria utilizar cache?
Introdução
"A música de um filme deve ser mais sentida do que ouvida pelo espectador. - David Raksin”
Sabe quando você acessa um app lento, onde cada toque na tela é uma espera interminável? E o contrário, uma experiência de usar um sistema rápido e responsivo que você nem percebe, pois tudo é tão fluído.
Por trás dessa fluidez, quase sempre existe um herói silencioso trabalhando nos bastidores: o cache. De forma simples, o cache é uma camada de armazenamento de dados de alta velocidade que guarda informações frequentemente acessadas, evitando a necessidade de buscá-las em fontes mais lentas, como um banco de dados.
Embora pareça uma solução mágica, o cache é, na verdade, um campo complexo de trade-offs. Uma implementação ingênua pode introduzir bugs sutis, inconsistências de dados e até falhas catastróficas. Compreender suas estratégias e perigos é crucial, pois definirá se ele realmente ajudará seu sistema ou se tornará um grande problema.
Pirâmide da Hierarquia de Memória
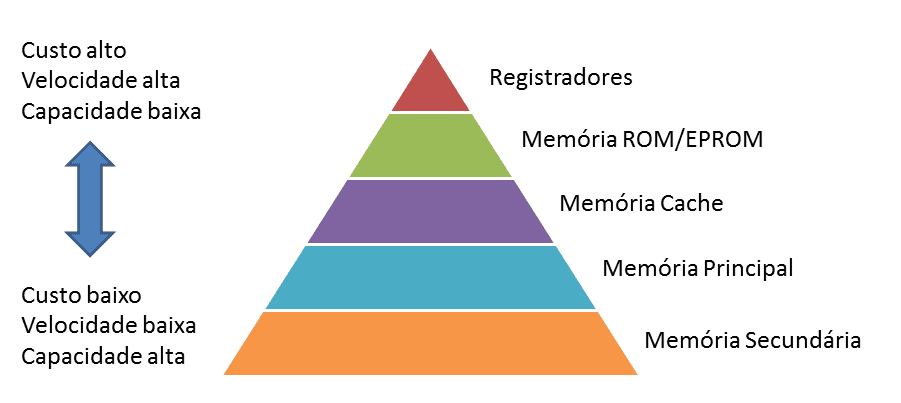
Para entender a verdadeira função do cache, primeiro precisamos olhar para um dos trade-offs mais importantes na arquitetura de computadores, que essa pirâmide ilustra perfeitamente. Pense nela como um mapa da relação entre velocidade, custo e capacidade.
A regra básica é:
Quanto mais rápido um tipo de memória, mais caro ele é por gigabyte e, consequentemente, menor é a sua capacidade no sistema.
O princípio do cache surge diretamente dessa hierarquia. A ideia é simples: para acelerar o acesso, nós copiamos temporariamente os dados dos níveis mais lentos e maiores para os níveis mais rápidos e menores.
1. O que é Cache?
O propósito principal de um cache não é simplesmente armazenar dados, mas otimizar a latência. Seu objetivo é servir como uma camada de memória de alta velocidade que diminui o tempo médio de resposta das consultas, mantendo os dados mais acessados prontos para entrega imediata. Esse mecanismo gera dois benefícios diretos e estratégicos:
- Reduz a latência média das consultas: Ao servir dados diretamente da memória, o cache evita a sobrecarga de consultar o banco de dados principal, uma operação significativamente mais lenta.
- Diminui a carga sobre o banco de dados: Ao absorver grande parte das solicitações de leitura, o cache permite que um cluster de backend menor suporte o mesmo tráfego, tornando a infraestrutura mais eficiente e econômica.
O impacto é duplo: a aplicação se torna visivelmente mais rápida para o usuário final e, ao mesmo tempo, mais econômica para a empresa.
No entanto, aqui surge o primeiro grande trade-off: um cache otimizado para latência pode sacrificar a disponibilidade. Se o cache falhar, toda a carga de leitura é transferida abruptamente para o banco de dados, que pode não estar dimensionado para suportar esse pico, levando a uma falha em cascata.
2. Como e Quando Atualizar Seus Dados
A eficácia e os riscos de um cache são definidos pela forma como os dados entram e saem dele. Cada uma com suas próprias vantagens e vulnerabilidades. Essas estratégias determinam o equilíbrio entre desempenho, consistência e complexidade.
Estratégias de Leitura
Cache-Aside (Lazy Loading)
Esta é a tática mais comum. A aplicação orquestra o fluxo da seguinte forma:
- Primeiro, a aplicação pergunta ao cache: "Você tem os dados para a chave X?".
- Cache Hit: Se o cache responder "Sim", ele entrega os dados e o processo termina.
- Cache Miss: Se o cache responder "Não", a aplicação se volta para o banco de dados, busca a informação, armazena uma cópia no cache para a próxima vez e, finalmente, retorna os dados ao solicitante.
Aqui, o trade-off é brutalmente claro: essa abordagem é ideal para cargas de trabalho com muita leitura (read-heavy), pois apenas os dados realmente solicitados são cacheados. No entanto, ela introduz dois problemas: os dados no cache podem ficar obsoletos (stale) e um cache miss resulta em uma operação mais lenta do que uma consulta direta ao banco.
Read-Through
Uma variação do Cache-Aside, a estratégia Read-Through move a lógica de busca do banco de dados para dentro do próprio cache. A aplicação consulta o cache, e se houver um miss, o próprio sistema de cache se encarrega de buscar os dados na fonte principal. Isso simplifica o código da aplicação, que não precisa mais gerenciar a comunicação com o banco de dados.
Estratégias de Escrita
Write-Through
Nesta estratégia, toda operação de escrita é feita simultaneamente no cache e no banco de dados, garantindo que o cache nunca contenha dados obsoletos.
Os trade-offs são significativos: a consistência dos dados é máxima, mas o desempenho da escrita é penalizado. Essa latência adicional na escrita não é apenas um número em um benchmark; em um sistema de alta concorrência, como um e-commerce durante a Black Friday, escritas mais lentas podem significar bloqueios de recursos mais longos, menor throughput e, em última análise, uma experiência de checkout frustrante para o cliente. Além disso, essa estratégia sofre com o "problema do cold start" (um novo nó de cache começa vazio) e pode desperdiçar recursos ao armazenar dados que talvez nunca sejam lidos.
Write-Back
Para otimizar a velocidade, a estratégia Write-Back (ou write-behind) atua de forma diferente: os dados são escritos primeiro no cache, que confirma a operação imediatamente, e só depois são persistidos no banco de dados de forma periódica (assíncrona).
| Estratégia | Principal Vantagem | Principal Desvantagem | Consistência dos Dados | Complexidade da Aplicação |
|---|---|---|---|---|
| Cache-Aside | Ideal para cargas de trabalho de leitura (lazy loading). | Dados podem ficar obsoletos; cache miss é mais lento. | Eventual (pode ficar obsoleto) | Maior (aplicação gerencia o cache) |
| Read-Through | Simplifica o código da aplicação. | Semelhante ao Cache-Aside, com maior latência no miss. | Eventual (pode ficar obsoleto) | Menor (cache abstrai o DB) |
| Write-Through | Alta consistência; o cache nunca fica obsoleto. | Escritas mais lentas; pode armazenar dados nunca lidos. | Alta (nunca obsoleto) | Menor (cache abstrai o DB) |
| Write-Back | Escritas extremamente rápidas; alto throughput. | Risco de perda de dados em caso de falha do cache. | Eventual (consistência atrasada) | Menor (cache abstrai o DB) |
3. Quando NÃO Usar Cache
Tentar usar o cache em certos cenários pode ser imprudente. Às vezes, a decisão de arquitetura mais inteligente é não usar um.
Aqui estão cenários onde o uso de cache é inútil ou perigoso:
- Informações Privadas: Nunca armazene em cache dados sensíveis que exigem verificação de permissão rigorosa a cada acesso, como detalhes de contas bancárias.
- Informações Públicas em Tempo Real: Dados que mudam constantemente e exigem precisão absoluta não devem ser cacheados. Exemplos incluem preços de ações, horários de voos ou a disponibilidade de quartos de hotel para o futuro próximo.
- Conteúdo Pago ou Protegido por Direitos Autorais: Itens como e-books ou filmes que exigem autenticação e autorização por usuário não devem ser colocados em um cache compartilhado, pois isso poderia contornar os mecanismos de controle de acesso e permitir que usuários não autorizados acessem o conteúdo.
- Requisições Únicas: Se as solicitações ou suas respostas são sempre únicas e nunca se repetem, o cache não oferece nenhum benefício de desempenho, pois nunca haverá um cache hit.
Seja pragmático: nesses cenários, introduzir um cache não é uma otimização, é uma sobrecarga de engenharia que adiciona complexidade e risco sem nenhum benefício tangível.
4. E se o seu Banco de Dados for Apenas um Cache?
Tradicionalmente, vemos o banco de dados como a "fonte da verdade", o repositório final de todos os dados. No entanto, uma perspectiva diferente, popularizada por autores como Martin Kleppmann, inverte essa lógica. Ela é resumida famosa citação de Pat Helland:
"A verdade é o log. O banco de dados é um cache de um subconjunto do log."
A ideia é que a verdadeira e imutável fonte de verdade de um sistema não é seu estado atual, mas sim um log de eventos, uma lista sequencial de tudo o que já aconteceu. Pense em um sistema de contabilidade. A "verdade" não é o saldo atual de uma conta; isso é apenas um estado temporário.
A verdadeira fonte de verdade é o livro-razão (o log de eventos), uma lista imutável de todas as transações (débitos e créditos) que já ocorreram. O saldo atual é apenas uma visualização materializada, um "cache", derivado da reprodução desse log. Se o banco de dados que armazena os saldos for perdido, ele pode ser perfeitamente reconstruído a partir do livro-razão.
Essa perspectiva radical reenquadra toda a nossa discussão. Se o próprio banco de dados é apenas um cache de um log, então as estratégias que discutimos na Seção 2 não são apenas sobre cachear um banco de dados; são sobre criar caches de um cache.
Isso destaca a natureza fractal do cache em sistemas modernos e nos força a pensar de forma ainda mais crítica sobre onde reside a "verdade" final. O banco de dados deixa de ser uma entidade sagrada para se tornar uma peça substituível e reconstruível.
Conclusão
O cache é uma ferramenta indispensável, mas seu poder não está na simples implementação, e sim no gerenciamento cuidadoso de seus trade-offs.
Cada decisão, desde a escolha de uma estratégia de leitura ou escrita até a definição de quais dados merecem ser cacheados, é um cálculo que equilibra velocidade, consistência, custo e complexidade. Entender esses equilíbrios é o que separa uma otimização bem-sucedida de uma nova fonte de problemas.
Portanto, a pergunta que você deve se fazer não é "devo usar um cache?", mas sim "qual problema estou realmente resolvendo com ele?".
💡 Quer aprender mais sobre Next.js?
Confira meus cursos práticos e aprenda a criar aplicações profissionais do zero.
Ver CursosCurtiu? Compartilhe esse post: